Intro
https://zju3dv.github.io/neuralrecon/
NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video
Pipeline overview NeuralRecon predicts TSDF with a three-level coarse-to-fine approach that gradually increases the density of sparse voxels. Key-frame images in the local fragment are first passed through the image backbone to extract the multi-level feat
zju3dv.github.io
일명 NeuralRecon이라고 불리는 논문에 대한 리뷰입니다. TSDF based model로 지금까지의 tsdf based 모델에 큰 영향을 준 coarse to fine구조를 제안하였으며, GRU Fusion모듈을 통해서 global한 3D 전체 volume을 구성하려고 한 모델입니다. 2021 CVPR oral paper이며, Atlas (ECCV 2020) 라는 모델 이후 TSDF-based 모델 중 가장 baseline이 되는 모델입니다. 요즘 각광받는 Neural radiance 기반의 모델이 아니라, 3D CNN을 이용한 general한 3d scene 생성모델이라고 생각하시면 될 것 같습니다.
3D 배경지식
image등을 통해서 3d mesh나 pointcloud를 재생성하는 구조로써 Neural Recon에 대한 소개 이전에 Mesh, Voxel등의 간단한 내용요약하겠습니다.
Mesh
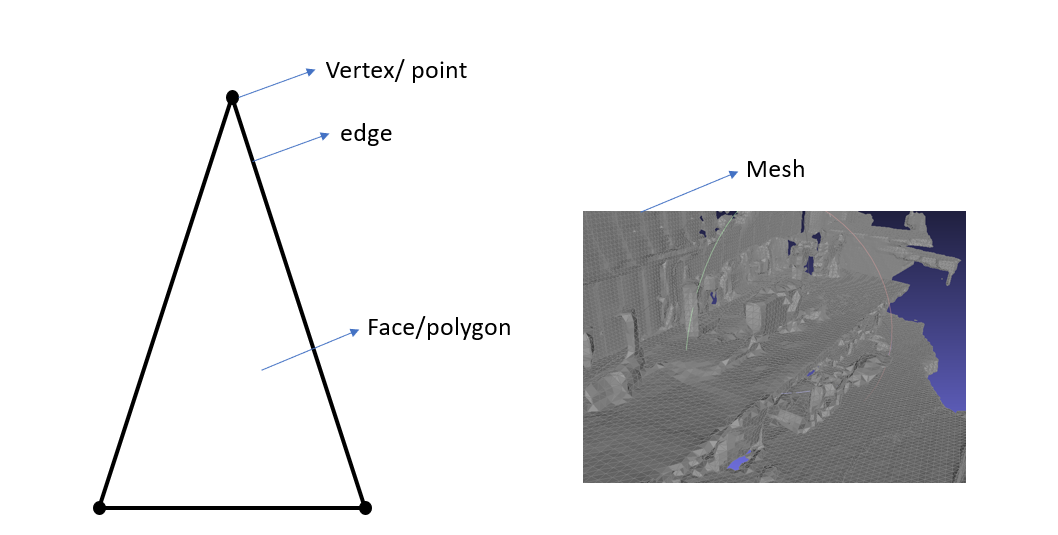
- 3D공간을 표현하는 형식으로 3D 공간상에 존재하는 점들(Vertex/ Point) 과 그 점 3 개의 집합인 면(Polygon/face)들로 이루어진 3D 공간 표현방법
Voxel
-3D 공간을 표현하는 Mesh 나 PointCloud 의 경우 순서가 없고 (Unordered) 희소 (Sparse)한 특징이있음
-이미지의 pixel 처럼 3D 공간을 표현하기 위해서 3D공간을 작은 단위공간으로 쪼갠 것 --> 3차원 공간을 grid로 쪼갰다고 보면 편함 (마인크래프트)

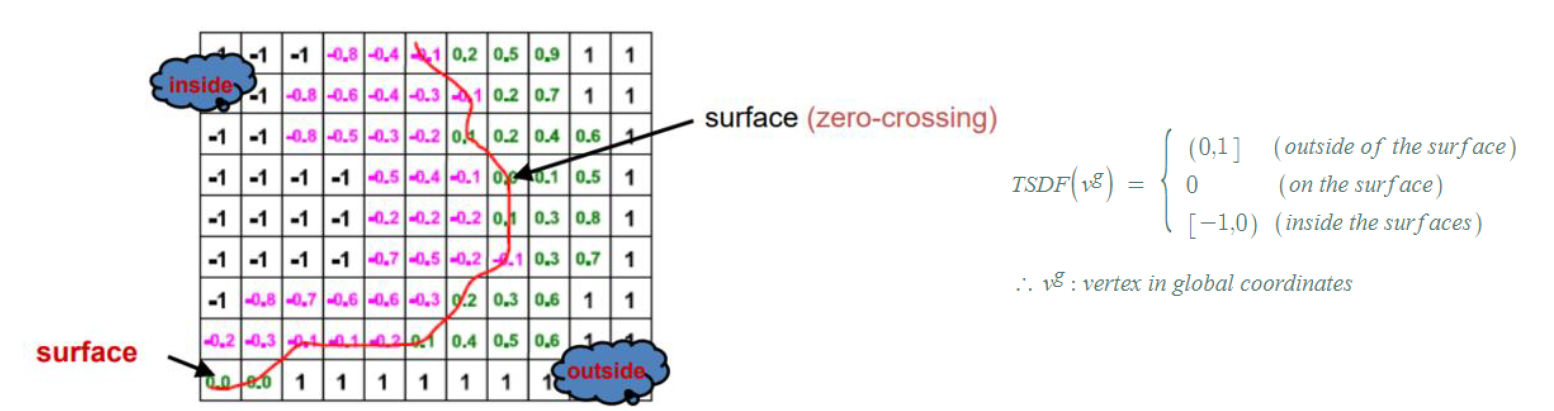
TSDF (Truncated Signed Distance Function)
- 3D scene reconstruction의 목적은 Surface 를 찾아 recon 하는 것인데 이때 surface 를 표현하는 함수를 SDF 라고 함
- Voxel 형태로 단위공간을 나누어 surface 라고 판단되는 곳은 0, Surface 안쪽은 음수 , Surface 바깥쪽은 양수로 표현하는 방식
3D Scene Reconstruciton의 종류
3D scene reconstruction의 종류는 pointcloud에서부터 mesh를 생성하는 것, sparse 한 pointcloud에서 fine한 pointcloud를 생성하는 것 등등이 많지만, 여기서 말하는 3d reconstruction은 RGB Video를 이용해서 여러가지의 이미지를 input으로 받아 3d reconstruction을 하는 방법입니다. 3D reconstruction은 크게 3가지 방법을 통해서 연구가 되었는데요
1. Depth-based (MVS) method
2. TSDF based method
3. radiance field based method
로 구분할 수 있습니다.
Depth-based method는 말그대로 depth를 예측한 이후 이 depth map을 통해서 reconstruction을 하는 방법이구요, tsdf based는 depth예측없이 바로 tsdf를 예측해서 reconstruction을 하는 방식입니다. radiance field based method는 Nerf를 기반으로 한 방법으로 Neus등의 논문들이 소개되었는데, 이에 대해서는 나중에 따로 리뷰를 하도록 하겠습니다.
Method
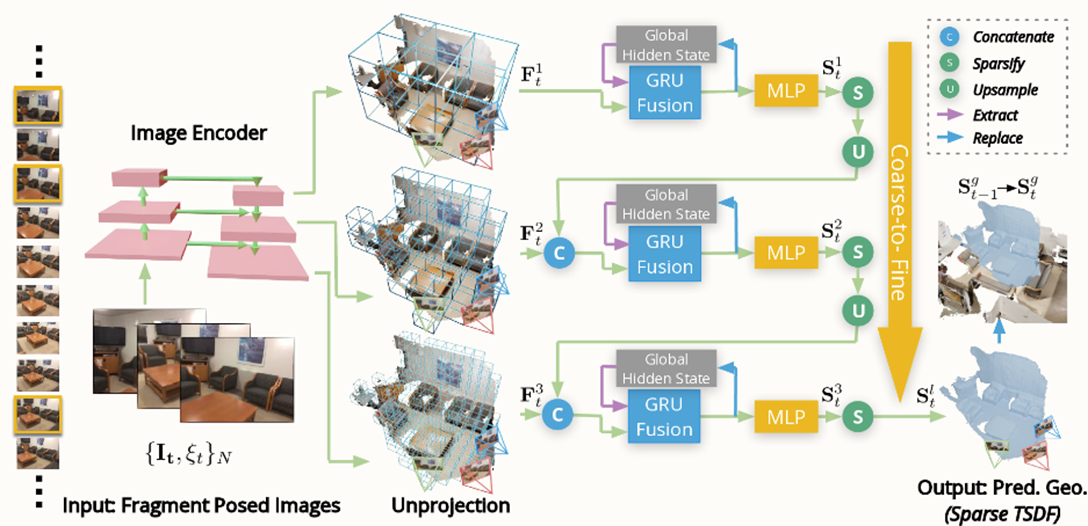
NeuralRecon의 contribution 3가지를 정리하자면 다음과 같습니다.
- Three level coarse-to-fine approach
- TSDF based 3d reconstruction
- GRU Fusion for global 3D volume
Dataset
Scannet V2
input: RGB video and camera parameters
output: 3D TSDF volume
GT: three level tsdf volume
앞에서 얘기했듯이 세개의 레벨로 3d reconstruction을 하게 되는데 coarse medium fine의 세 레벨로 recon을 진행합니다. 따라서 이에 따라 gt값으로 3개의 레벨에 해당되는 tsdf volume을 전처리로 만들어 gt로 사용합니다.
Key frame selection/ 2d backbone
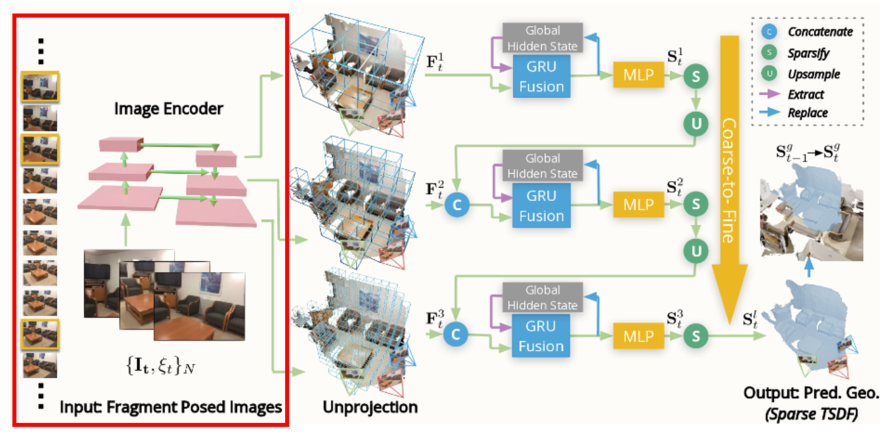
- 비디오의 전체 frame이 input으로 처리되면 computing cost가 높아지는 문제가 있기 때문에 같은 곳을 바라보는 이미지(t_max의 시간) 중에 R_max이상의 각도를 갖는 N개의 이미지를 선택하여 2D image encoder에 집어넣음
- 논문에서는 N=9를 이용하였으며 9개의 이미지 concat되어서 Mnasnet으로 구성된 U-Net에 input으로 들어감.
- U-Net의 각 level의 output을 이용해서 coarse to fine까지의 feature를 이후 volume construction에 이용할 예정.
Image Feature Volume Construction
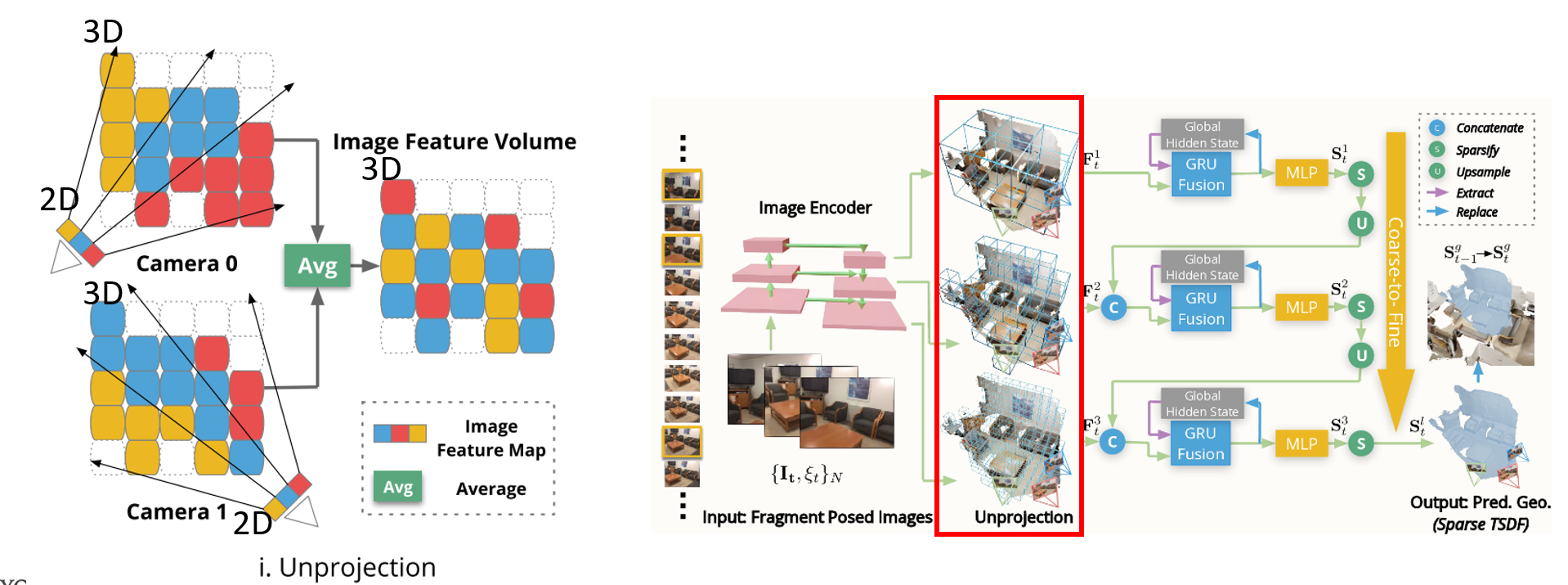
- N개의 이미지를 통해 2D backbone을 통과한 Image feature는 back-project를 통해 해당하는 3D volume에 할당된다. 이후 averge pooling을 통해 3차원 grid에 맞는 feature가 들어가게 됨.
GRU FUSION

시간에 따라 진행되는 비디오의 특성상 t시간에 비치는 공간을 지금까지 만든 global volume과 합치는 과정이 필요함
따라서 이전에 예측한 global volume에서의 bounding volume과 t시간에 예측해야하는 local volume에 대한 feature를 합쳐서 hidden state를 update함
Loss

TSDF Loss
-L1 loss
-각 voxel마다 값이 지정되어 있으므로 L1 loss 사용가능
Occ Loss
-Voxel occupancy loss
- volume이 차 있으면 True 차 있지 않으면 False로 해서 BCE loss사용
Results

F-score를 보면 이 논문이 발표될때까지의 다른 3d reconstruction에 비해 압도적으로 높은 성능을 보여주며, Tsdf-based model은 이때까지 Atlas (http://zak.murez.com/atlas/) 만이 유일했습니다. Atlas에 비해 빠른 속도와 정확한 recon성능을 보여주는 것을 확인할 수 있었습니다.
Limitations
후속 연구
Transformerfusion (NIPS 2021)
https://arxiv.org/pdf/2107.02191.pdf
Vortx (3dv 2021)
https://arxiv.org/abs/2112.00236
등의 논문이 존재합니다.
내용에 문제가 있으면 댓글부탁드립니다.