※ 아이디어 위주로 논문을 겉핥은 글입니다. 오류가 있으면 댓글로 알려주세요
#1 SECOND 논문의 의의
Point Net의 발표이후 point cloud를 이용한 3d obect detection에 대한 논문들이 연이어 발표되었다. 특히 3d object detection의 방식은 point net++를 이용한 point-based method와 voxel net(2018, IEEE)을 기반으로 한 grid-based method방식으로 나누어졌다.
SECOND 논문은 grid-based방식을 크게 발전시킨 SP CONV에 대해 소개한 논문이다. SP CONV방식은 computing cost를 매우 줄일 수 있는 방식으로 실시간 detection이 매우 중요한 자율주행에서의 object detection에서 매우 효과적이다. 그렇기 때문에 현재 grid-based method방식을 이용하는 대부분의 detection방식에 SP CONV가 적용된다.
#2 Grid-based method란?
Grid-based method란 마치 image의 pixel처럼 point cloud 정보를 voxel이라는 단위로 나누어 voxel의 feature를 input으로 하여 3d CNN을 적용하는 방식이다. 그러나 Point Cloud는 대부분의 공간이 비어있고, 점이 존재하는 영역은 약 10%에 불과하다(이러한 특성을 sparse하다고 한다).
그렇기에 3d CNN을 이용하여 object detection을 처리하는 방식을 처음 소개한 voxel net에서는 불필요한 computing cost를 줄이기 위해서 sparse한 정보들을 빽빽하게 해주는 방식을 통해 3d CNN을 적용한다. 이에 대해 더욱 자세한 설명은 voxelnet 논문을 한 번 읽어보는 것을 추천한다.
Grid-based method에서 가장 중요한 것은 3d 공간을 voxel이라는 단위체로 나누어 각 voxel의 feature를 추출하고 그 feature를 이용하여 3d CNN을 적용한다는 것이다.
#3 SECOND

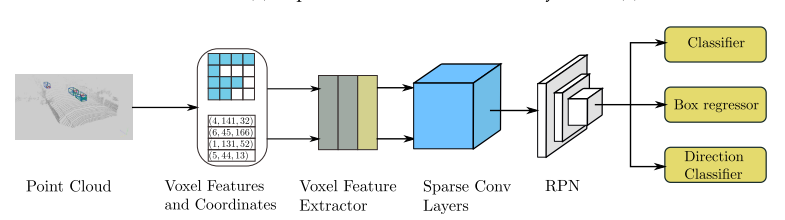
SECOND detector의 구조는 아래와 같다. 기본적인 구조는 위에 첨부한 Voxel Net의 구조와 매우 유사한데 다른 점은 Sparse Conv Layers라는 것을 확인할 수 있다. Voxel Net에서의 Convolutional Middle Layer가 Sparse Conv Layer로 바뀐 것을 확인할 수 있는데 이 Sparse Conv Layer에 대해서 이해하는 것이 가장 중요할 것이다.
#4 Sparse Conv Layers

위의 그림이 논문에서 Sparse Conv Layer에 대해 설명한 그림이다. Sparse Conv는 매우 sparse한 data인 point Cloud의 문제를 해결하는데 매우 효과적인 방식이다. 위의 그림을 보면 Rule등 처음 보는 용어들이 많이 있는데 이 그림을 간단한 예시를 통해서 다시 한 번 표현해 보자. (지금부터 Sparse Convolution을 SP Conv라고 줄여서 표현하겠다.)

맨 왼쪽의 그림에서 빨간색으로 채워져있는 칸 만이 정보가 존재하는 voxel이다. 나머지 voxel들은 다 정보가 존재하지 않는 voxel이다. input중에서 (1,2)의 좌표에만 정보가 존재하는 것이다. 이러한 5x5의 input에 3x3의 CNN filter가 padding없이 계산한다면 3x3의 output이 나온다는 것을 알 수 있다.
그러나 이렇게 정보가 많이 비어있는 input을 모두 CNN filter가 지나가면서 계산한다는 것은 시간이 많이 소요되는 일이다. 이런 일을 방지하기 위해 SP Conv 방식에서는 Rule이라는 것을 만든다. filter가 맨 처음 input과 계산될 때, 그림에서 보이는 것과 같이 input의 좌표 (1,2)는 filter의 좌표 (0,1)과 계산된다. 또한 이 결과로 output의 좌표 (0,0)에 그 계산 값이 저장되게 된다.
다시 정리해보면 input의 좌표 (1,2) x filter의 좌표 (0,1) -> output의 좌표(0,0) 이라는 하나의 규칙이 생기게 되는 것이다. 이렇게 input좌표 (1,2)의 결과로 바뀌는 output의 좌표는 (0,0), (1,0), (0,1), (1,1), (0,2), (1,2) 총 6개만이 존재한다. 따라서 input 좌표 (1,2)와 관련된 rule은 총 6개가 존재하게 된다. 이렇게 SP CONV는 기존의 CNN이 총 9칸 x 9번의 계산으로 81개의 계산이 필요하는 것과 다르게 총 6번의 계산을 통해서 feature를 추출할 수 있다.
위와 같이 정보가 충분히 많은 voxel만을 계산하는 3d Sparse Convolution을 이용하여 SECOND는 획기적으로 시간을 줄일 수 있었다.
#5 Experiment

SECOND가 발표된 당시 kitti Dataset을 이용한 evaluation결과이다. Voxel Net보다 무려 5배가까이 빠른 속도를 보이는 것을 확인할 수 있다. VFE layer(voxel Net참조)의 크기를 조절하여 SECOND 모델은 모델의 크기에 따라 2개로 나누어지진다. 큰 모델은 약 20FPS의 속도를 가지며 작은 모델은 약 40FPS의 속도를 갖는다.

Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. https://doi.org/10.3390/s18103337
'Computer Vision Paper > 3d Object Detection' 카테고리의 다른 글
| SA - SSD : Structure Aware Single-stage 3D Object Detection from Point Cloud 리뷰 (1) | 2021.08.10 |
|---|---|
| POINT NET 리뷰 (0) | 2021.01.26 |

